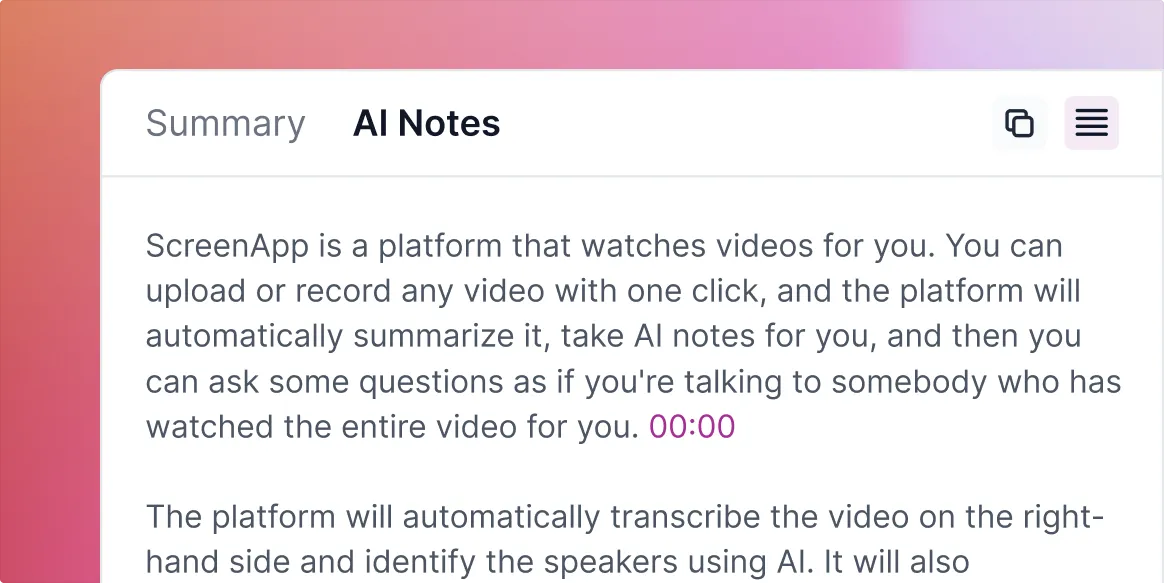
Accurate and efficient transcription of multiple speakers made easy with ScreenApp's AI-powered video platform. Say goodbye to manual transcriptions and save time with our advanced technology.

.webp)
.webp)

- Diarise your transcripts with AI
- FIx Overlaps with intelligent categorisation
- Customise output with Speaker IDs

世界中の企業から信頼され、サポートされています



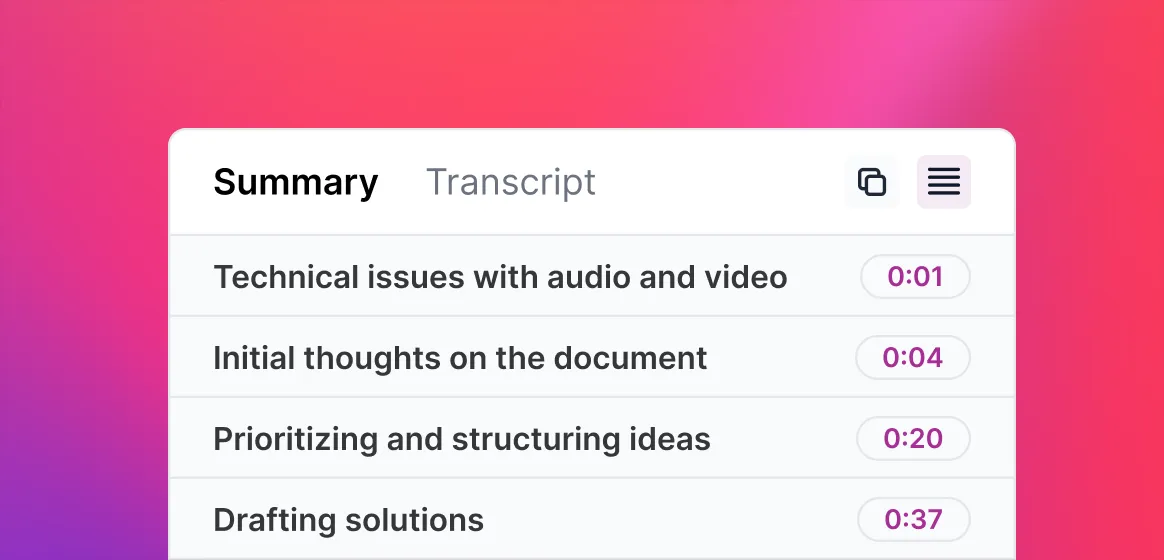
Step 1: Upload your video
Begin by uploading the video file that you want to transcribe. Make sure the video is in a compatible format and accessible on your device.
Step 2: Transcription process
Once the video has been uploaded, the transcription process will automatically begin. This may take a few moments depending on the length of the video.
Step 3: Identify speakers
After the transcription is complete, you need to identify the different speakers in the video. This step is crucial for accurate multispeaker transcription.
Step 4: Use ScreenApp to identify speakers
Utilize ScreenApp, a powerful tool designed specifically for multispeaker transcription. It will automatically identify and label the speakers in your video.
Step 5: Export and share
Once the speakers have been identified, you can export the transcription in text format. Simply copy the transcribed text and save it for further use.
Step 6: Transform, translate, search, and reformat
Take advantage of ChatGPT AI, a versatile tool that allows you to transform, translate, search, and reformat the transcribed text. This step helps you enhance the transcription's usability and accessibility.
By following these steps, you can successfully transcribe a multispeaker video and utilize various tools to enhance and manipulate the transcribed text according to your specific needs.
手作業による文字起こしの時代は終わりました。当社の最先端のAIが、ビデオやスクリーンレコーディングの文字起こしをシームレスに処理します。正確な文字起こしをアップロードして、すぐに受け取ることができます。
当社のプラットフォームは幅広いファイル形式をサポートしているため、最新のポッドキャストエピソードから会議での基調講演まで、あらゆるものを書き起こすことができます。ファイルをアップロードするだけで、あとは当社にお任せください。互換性の問題を心配する必要はもうありません。すべて私たちが処理するので、お客様はコンテンツに集中できます。
AIを活用した翻訳サービスで、コンテンツを複数の言語に正確かつ簡単に翻訳できます。私たちの支援により、リーチを最大化し、簡単にコミュニケーションを取り、世界中の視聴者を引き付けることができます。
動画の中でパーフェクトな瞬間を見つけるのは大変な作業です。しかし、当社の直感的なインターフェイスでは、トランスクリプトを使って簡単に動画のナビゲートやトリミングができます。特定のセクションをハイライトしたいですか?トランスクリプトからその部分を見つけて、直接トリミングしてください。これにより、重要な瞬間を簡単に抽出、共有、紹介できます。
1つのサイズですべてに対応できるわけではありません。特にメディア形式の場合はそうです。私たちのプラットフォームはそれを理解しています。無数のファイル形式をサポートしているため、最新のポッドキャストエピソードからカンファレンスでの基調講演まで、あらゆるものを自由に書き写すことができます。互換性に制限されることはありません。ご希望の音声または動画ファイルをアップロードするだけで、あとは当社のプラットフォームにお任せください。
Accurate and Efficient Transcription of Multiple Speakers Made Easy
ScreenApp's AI-powered video platform offers a highly accurate and efficient solution for transcribing multiple speakers. With our advanced technology, you can say goodbye to manual transcriptions and save valuable time.
99% Accuracy Guarantee
At ScreenApp, we understand the importance of accuracy in transcription. Our AI algorithms have been trained extensively to achieve an impressive accuracy rate of 99%. You can rely on our platform to provide precise transcriptions, ensuring that every word spoken by multiple speakers is captured correctly.
Lightning-Fast Transcriptions
Time is of the essence, and we value your productivity. With ScreenApp, you can have your transcriptions ready in just a few minutes. Our advanced technology processes audio and video files swiftly, allowing you to access the transcriptions promptly and proceed with your work without delay.
No Charges Based on Minutes
Unlike many transcription services, ScreenApp does not charge based on the duration of your audio or video files. We believe in providing transparent and cost-effective solutions. With us, you can enjoy unlimited transcription services without worrying about additional costs based on minutes.
Choose ScreenApp for accurate and efficient transcription of multiple speakers. Our AI-powered video platform ensures fast and reliable transcriptions, saving you time and eliminating the need for manual transcription. Experience the convenience and accuracy of ScreenApp today.
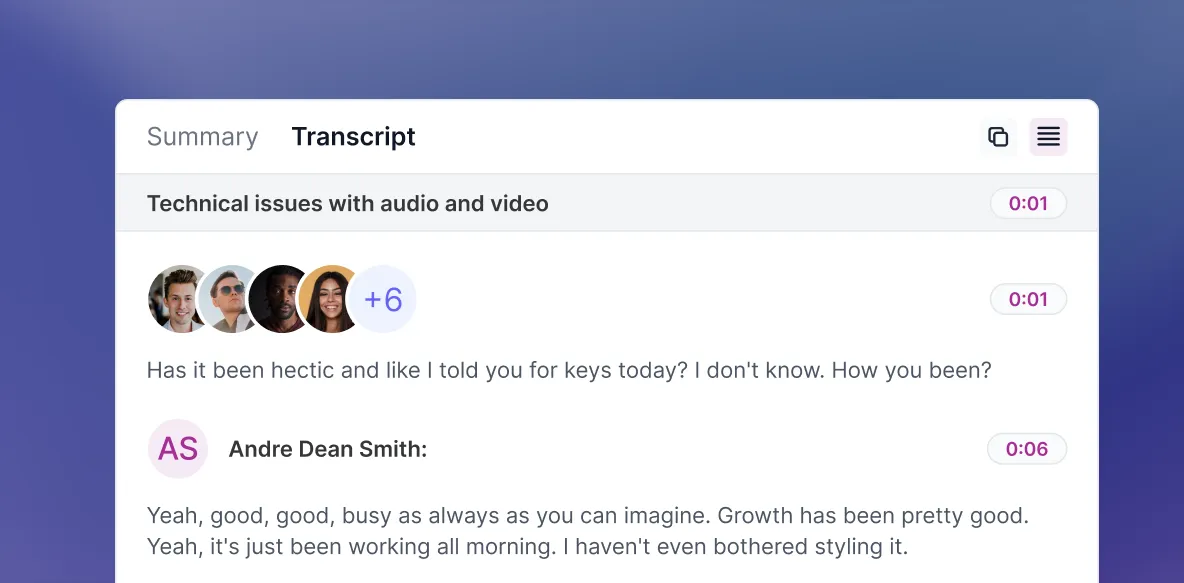
Q: What does "speaker identification" mean in transcription?
A: Imagine a bustling restaurant conversation. Speaker identification in transcription pinpoints who's speaking at each moment, labeling each voice like name tags at a party.
Q: How does ScreenApp identify speakers?
A: Our advanced AI analyzes audio cues like pitch, timbre, and speaking patterns to distinguish and track individual voices, even in complex conversations.
Q: How are speakers labeled in the transcript?
A: You can choose! ScreenApp offers flexible options like generic labels ("Speaker 1," "Speaker 2"), customized names ("John," "Jane"), or even speaker IDs for nuanced identification.
Q: How accurate is ScreenApp's speaker identification?
A: Accuracy depends on factors like audio quality, number of speakers, and background noise. However, ScreenApp boasts industry-leading technology with a focus on continuous improvement.
Q: What are the benefits of speaker identification?
- Effortless reference: No more wondering who said what. Jump to specific speaker sections or analyze individual contributions.
- Enhanced accessibility: Transcripts become valuable for those with hearing impairments or language barriers.
- Deeper content analysis: Analyze individual speaker dynamics, identify key contributors, or track specific arguments.
Q: How does ScreenApp compare to traditional transcription methods?
A: Traditional methods often require manual speaker identification, a tedious and error-prone process. ScreenApp automates the task, saving you time and ensuring accuracy.
Q: What are the basic rules of transcribing?
A: While ScreenApp handles the heavy lifting, understanding basic transcription principles like punctuation, speaker labeling, and timestamps can further enhance your transcript's usefulness.
Q: Can ScreenApp identify any voice?
A: While technology is continuously evolving, perfect accuracy across all situations is still under development. However, ScreenApp strives to offer the best possible identification performance with ongoing advancements.
